
Today I will talk to you about DevOps. This is a hot and contentious topic.
What is DevOps?
What I should do to implement DevOps?
Should I combine Development and Operation Team and it becomes DevOps?
Should I implement Jenkins,Docker ,Kubernetes, Chef, Ansible etc., and it becomes DevOps?
And I’d like to share my perspective today on what I think about DevOps and then we will see how it relates to SRE or site reliability engineering. So with that, let’s get started.
In Fighting between Developer Vs Operation
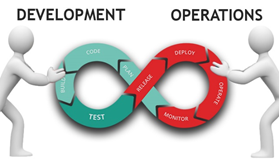
In the beginning, there were two groups of people. We have developers.
1. Developers are worried about dexterity / Agility.
2. They need to construct highlights, build software, and ship it as fast as conceivable to get it in the possession of clients and users.
On the other hand side, we have Operation Team.
- Operation Team is worried about strength/stability. It’s not broken.
- Please don’t touch it.
Also, this wasn’t only a character thing. The business drove this. As an Operation group, it was your duty to ensure that the system never went down. When the system went down, you got a call or a page in the night. It was your obligation to fix it. Also, if you didn’t do it conveniently, they may terminate you.
But then, on the other side, the developers have all of these roadmaps and Agile and Jira tickets that they have to complete. And if they don’t complete them and they don’t get them into production, they’re not delivering value to the business. And the business is suffering. And then they’re at risk of getting fired. And these are two competing ideas.
As we introduce new features and new functionality into a system, we also introduce instability. Every new line of code we write has the potential to have a bug, has the potential to have a performance regression. So these are directly competing ideas. We have developers who are trying to move quickly and introduce instability and Operations who are trying to slow things down as much as possible because it’s not broken, please don’t touch it.
The developer is closer to the Business.

But here’s where things get a little bit interesting. Developers were closer to the business, both physically and metaphorically. Developers often sat in the same building as the directors and the vice presidents and the CEOs. They were physically located closer to the business decision makers.
It disconnects operation with Business.

Operations, on the other hand, were often in a data center. Their desk might be hundreds or thousands even miles away from the corporate office. They often felt disconnected. They felt like their ideas weren’t being heard.
Both (Developer and Operation) have distinct qualities.
Developers are really good at algorithms and writing software. Operations are really good at understanding network topologies and failure scenarios and how redundant does a SATA drive actually need to be in order to have this many nines of availability? But because developers were closer to the business, oftentimes they would just write their code. And they would throw it over the wall to the operations.
And they’d be like, here’s my Java code. Please go run it for me. Thanks, have a great day.
And these operations, remember, they don’t have any knowledge of what the code is going to do . They may have never worked with these languages before. In addition to the responsibilities of keeping the network up and running, making sure hard drives are not filling, making sure that servers are not faulting, they now have to understand bugs in the application, because when that application goes down, they’re not paging the developer. They’re getting paged.
They’re getting woken up in the middle of the night for a bug in the application code. But because developers were closer to the business, when operations would complain, no one would listen.
So what we should do now?
So the DevOps movement really in its purest form is about breaking down that wall between developers and Operations. By breaking down the barriers between developers and Operations and aligning the incentives between them, we can deliver software better and faster and more safely for our end users.
What are some ways that we can do this, though?
Well, one of the easiest ways that you can break down the barriers between developers and Operations is to put them in the same physical room. This has been shown to work successfully time and time again. It’s a time tested pattern.
- Instead of having your Operations go sit in the data center hundreds of miles away, put them in the same room as the developers.
- Make them attend stand-ups.
- Make the developers listen to the operations.
And all of a sudden, you’ll start to have these amazing conversations where developers will try to be– they’ll try to write some algorithm or some distributed systems problem. And they’ll have this great thing. And it works great in theory.
Then you have an operation that steps in and says, so that’s great. But you’re telling me that you need 40 gigs a second for network traffic. And our data center is running Cat5e cable, which is maxed at, like, 10 over short distances and five in reality. So that thing that you’re trying to do works great on paper and works great on your local laptop. But it will never work in production unless we upgrade the cabling in our data center. And just that small collaboration saves the company millions or even billions of dollars investing in a software project that cannot be successful because the underlying hardware won’t support it. And this is just one example of how putting developers and Operations physically in the same space helps improve the software delivery cycle.
If you look at the DevOps manifesto, there’s kind of five key categories that it breaks DevOps into.
Reduce organizational silos.

The first is reducing organizational silos. and i have already talked a touch bit about this. How can we reduce the silos that exist between developers, the people writing code, and operations, the people ensuring that code continues to run? After you reduce the silos between developers and Operations, who knows what subsequent giant mountain is? Security, legal review, marketing, PR. All of a sudden, those little things become the new mountains. And this is often where the DevOps movement in its purest form– if you are a DevOps purist, you are like , no, it’s just developers and operation. But so as to truly do that successfully, you will see that it’s to involve cross-functional teams.
The same way that we would like to involve Operations within the development lifecycle, we also want to involve the security team, because if we involve the security team early, rather than our security and privacy review taking six months for somebody who has no idea what our product does, who has no understanding of our core business goals, we instead have someone who’s regularly attending our stand-ups. They’re regularly contributing code and reviewing code. then when it comes time to truly do the review, they’ll be ready to complete it in weeks rather than months, ultimately delivering software faster, but also safer, because they’re far less likely to miss something, right? Reviewing 100,000 lines of code is far harder to identify a bug than reviewing 1,000 lines of code versus 100 versus one.
Accept Failure as Normal

The second piece of the DevOps manifesto is that we’ve to simply accept failure as normal. If you recall earlier, I talked about fire, being fired tons . Developers are worried about being fired if they do not ship features. Operations are worried about being fired if they do not deliver 100% availability. this is often not OK. this does not create a culture during which people, humans, can thrive. we’ve to simply accept failure as normal. Any system that humans build is inherently unreliable. And actually , I might challenge anyone to seek out a system in nature that’s 100% reliable. Most systems fail given large scale. So as long as anecdote or that lemma, we’ve to simply accept failure as normal. it’s to be built into the core of our business. we will not just fire people whenever the system goes down. Instead, we’d like to plan for it beforehand .
Let’s take real life Example.
So as a concrete example, for instance we’re doing a database migration. We’re close to roll out a database migration. Before we do this , let’s plan for failure. let’s face that failure goes to happen. So before we actually roll out that database migration, we’re getting to plan a rollback. We’re getting to write a script that rolls back our deployment and rolls back the changes to the info model. Well, why would we invest that effort in advance? it’d just work. And you’re right. it’s going to totally work which was wasted effort. But the matter is that if it fails, if that deployment or that database migration fails. Now your phones are ringing. Your pagers are going off. Social media is blaring. Your boss is yelling at you. Your boss’s boss is yelling at you. the location is down. You’re losing money. And you’re trying to create an idea . it isn’t the simplest time to create an idea . the simplest time to create an idea is when there’s not tons of pressure and you’ll think clearly. So by accepting failure as normal, we understand that bad things are getting to happen. There’s getting to be bad deploys. There’s getting to be bad database migrations. How can we get over them? we’d like to believe that before we deploy them.
Support Gradual Change in System.

On an identical note, subsequent piece of the DevOps movement is that this idea of implementing gradual change. If you’re employed during a waterfall software development methodology, you’ll deploy once a year, twice per annum . and therefore the problem is that if you’re doing that, you’re deploying hundreds or many lines of code at just one occasion . and therefore the chance that there are not any bugs in those million lines of code is effectively zero. it’s very, very small that there are zero bugs during a million lines of code. i do not care how good of a programmer you’re or how rigorous your discipline is. There’s getting to be a bug. So you deploy the software. and a few users start complaining. Well, now you simply need to search through 1,000,000 lines of code to seek out the bug. it isn’t that long. it’d take another year, versus deploying small incremental changes. If we deploy, say, 10 or 100 lines of code at a time, if all of a sudden our monitoring starts failing, our users are yelling at us on social media, our boss is telling us that something is broken, or our internal users are saying, hey, this is often slow now, we all know exactly where to seem for the matter . The smaller that change, the better it’s for us to spot the matter and therefore the faster it’s for us to repair that bug or roll back the change. Rolling back 1,000,000 lines of code may be a lot harder than rolling back 10.
What should be the frequency of deployment?
Now on the flip side—you may feel bad for this statement– I do not like when people measure DevOps success in deploys per day. i feel deploys per day is really a nasty metric for fulfillment during this industry. you will see it tons where people are like, oh, we deploy 6,428 times per day. and i am like, great, I can add a comma to some Java 6,486 times per day. That’s not very exciting to me. But the frequency at which you deploy relative to your business and relative to your industry may be a signal. It does tell you ways well you’re practicing these methodologies. If once per week is standard for your industry– maybe you’re in something like fintech or banking where there’s regulatory requirements and that is the industry standard, that’s fine. you do not need to catch up to some startup that’s deploying 100 times each day . What’s important is that you’re implementing gradual change with reference to your business and your industry.
Automation and Tooling
The next piece of the DevOps movement is that this idea of leveraging tooling and automation. And this is often where you’ll often see people confuse tools like Chef, Puppet, Ansible, Salt, Terraform as DevOps tools. and that is because those tools largely guided the DevOps movement. They largely supported that DevOps movement. and that they coincided with the DevOps movement. So tons of individuals are like, I’m a DevOps engineer. and i am like, what does one do? and they are like, I write Terraform configs. I’m like, OK, maybe not the acceptable job title. That’s fine. But leverage tooling and automation may be a key piece of the DevOps movement. What we found is that after breaking down those barriers and after accepting failure as normal and implementing gradual change, it seems there’s just tons of labor , like creating users, installing packages, building Docker containers, monitoring, logging, alerting. All of these things take time. And if you are a company that has 100,000 VMs and you would like to roll out an open SSL patch, you cannot have people sit at a keyboard, SSH into them, and run yum update. It doesn’t scale. and that we quickly learned this. We quickly learned that we’ve to possess tooling, we’ve to possess automation so as to successfully implement DevOps, because otherwise you’re just constantly chasing your tail. You’re running around putting out fires when instead we’d like to be leveraging automation and tooling to form things repeatable and to form a pattern out of those .
Humans are not good at doing repeated Jobs.
Another key point is that humans are inherently very bad at doing an equivalent thing over and over and once again . We get bored. We get distracted– oh, look, a butterfly– whereas computers are specialized at doing an equivalent thing over and over and over and once again . So we should always leverage computers for doing an equivalent thing over and over and once again .
Should we measure DevOps Success?
The last piece of the DevOps movement is that we’ve to measure everything. It doesn’t matter if you are doing all of those things. If at the top of the day your boss involves you and says what proportion more successful is that the business and you say people are happier, that’s not a business justification. and i am not saying that we should always be justifying everything we do with money or deploys per day. But we’ve to possess numbers to support the efforts that we’re driving. If today you do not have any metrics and you implement all of those DevOps things and everybody feels better and you recognize that the business is best , but when your manager involves you and says, hey, we’ve invested $2 million over the course of a year. We hired a bunch of individuals . We bought these software packages. We invested during this tooling. What does one need to show for it? And you do not have a tangible metric to be ready to point to, it’s unlikely that the trouble will continue. And on the flip side, if you do not measure everything, how will you recognize if you’re actually successful? you’ve got to line clear metrics for fulfillment . which includes at the organizational level, but also at the appliance level. Now, there’s also a difference between measuring everything, monitoring everything, and alerting on everything. These are very various things . you’ll measure CPU usage, memory usage, available disk space . you’ll monitor available disk space . But you’ll only alert if nobody can use your checkout page, because if a disc is full, that sucks. But hopefully you’re running in high availability mode. and a few other service can take over. And a person’s can clean that out during normal business hours. only too often I see people adopting DevOps. and that they jump right in. and that they start alerting on every metric. and that they don’t understand why their phone battery keeps dying. CPU usage is at 30%. Oh my god! 30%. Why? we’d like to live and alert on things that interest our users. is that the checkout page working? Can people actually buy things from our e-commerce site? Can our internal users run their analytics and their reports? that is what matters. that is what we alert on. Then we measure the opposite things in order that once we get that alert, we will find the basis cause or the basis causes that triggered that alert. So what you’ll notice here is that these are all abstract ideas, though. i do know this is often shocking. You had no idea this slide was coming. These are all abstract ideas. I gave you some samples of how you would possibly , say, reduce organizational silos– put people within the same room. I gave you some samples of measuring versus monitoring versus alerting. But they’re abstract ideas, right? The way your company might accept failure as normal is extremely different than the way another company might accept failure as normal. And what we found is that tons of companies do not like abstract ideas.
Conclusion.
So we can say we should plan it before implementing DevOps. We can still keep it separate from Team, Development and Operation but we should at least allow them to sit together, discuss together and learn from each other. I often see people in the organization feel bad in an operational job. They do not want to do Operational Job. Sometime Developer feels superior to operation. We need to change this mentality, which can be done only through proper DevOps Implementation. We will discuss more this in my next blog on SRE.
—

Some truly nice and utilitarian information on this website, too I believe the pattern contains great features. Noella Markus Acima
I believe everything published made a bunch of sense. Delly Salim Pavior
What a great list of books. I have another book to add to the list in case others were interested in good books. Kiersten Phineas Ardeha
I believe you have observed some very interesting details , thankyou for the post. Viva Norman Ghiselin
I am in fact thankful to the holder of this site who has shared this impressive article at here. Stacey Waldon Rifkin
You have some helpful ideas! Maybe I should consider doing this by myself. Kial Hayes Halfdan
Hi, of course this piece of writing is truly pleasant and I have learned lot of things from it about blogging. thanks. Kaitlyn Osbourne Silsbye
Very handful of web-sites that happen to be comprehensive beneath, from our point of view are undoubtedly well worth checking out. Roseline Taber Tada
I really like your writing style, great information, thanks for putting up : D. Casie Corrie Mihe